
Introduction
- Motivation
- Data Power Law: Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. However, these improvements through scaling alone require considerable costs in compute and energy.
- Data Pruning
- Aim to find a robust data pruning metric that can effectively rank the order of discarding ( or retaining ) training samples, in order to achieve a significantly reduced dataset size after pruning, while maintaining its high quality.
- Related Idea
- Core-set: Core-set is a “small data” summarization of the input “big data”, where every possible query has approximately the same answer on both data sets.
- Data Distillation (or Dataset Condensation): Given an original dataset, dataset distillation aims to derive a much smaller dataset containing synthetic samples, based on which the trained models yield performance comparable with those trained on the original dataset.

Related Works
Herding dynamical weights to learn (ICML 2009)
greedily select a set of pairs for coreset that are as similar as possible from other pairs already selected.
Active learning for convolutional neural networks: A core-set approach (ICLR 2018)
similar to herding except it selects the training examples to be as far apart as possible from each other
An Empirical Study of Example Forgetting during Deep Neural Network Learning (ICLR 2019)
findings
- a) there exist a large number of unforgettable examples, i.e., examples that are never forgotten once learnt, those examples are stable across seeds and strongly correlated from one neural architecture to another;
- b) examples with noisy labels are among the most forgotten examples, along with images with “uncommon” features, visually complicated to classify;
- c) training a neural network on a dataset where a very large fraction of the least forgotten examples have been removed still results in extremely competitive performance on the test set.
Algorithm

Experiment
unforgettable examples are less informative than others, and, more generally, that the more an example is forgotten during training, the more useful it may be to the classification task.
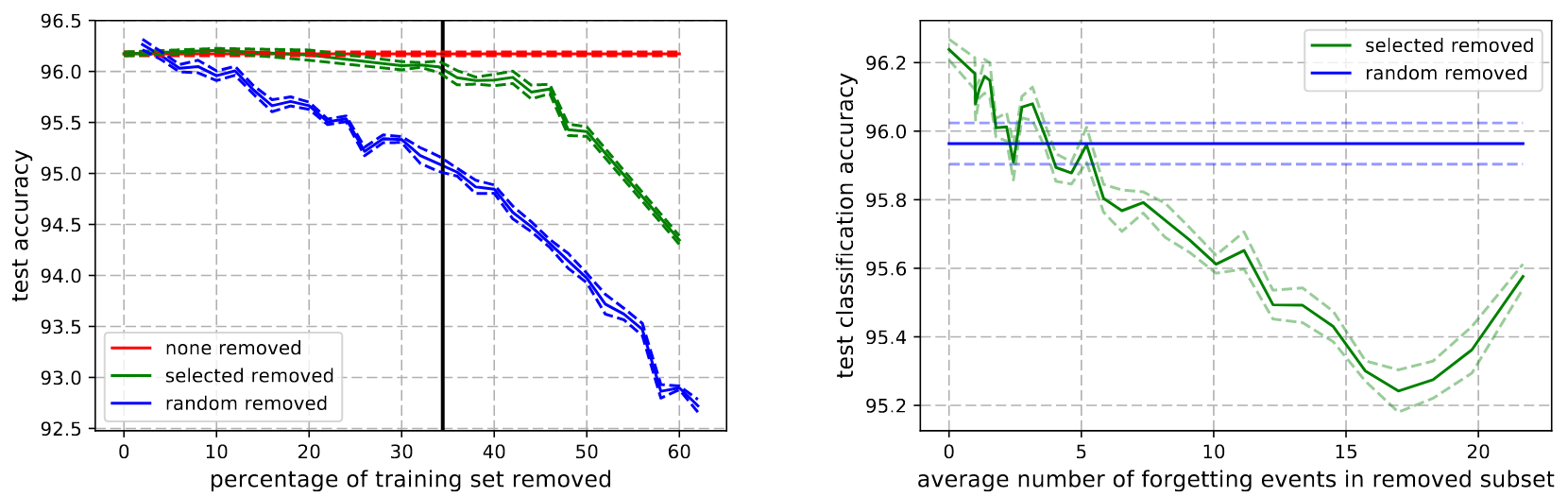
- Left Generalization performance on CIFAR-10 of ResNet18 where increasingly larger sub-sets of the training set are removed (mean +/- std error of 5 seeds). When the removed examples are selected at random, performance drops very fast. Selecting the examples according to our ordering can reduce the training set significantly without affecting generalization. The vertical line indicates the point at which all unforgettable examples are removed from the training set.
- Right Difference in generalization performance when contiguous chunks of 5000 increasingly forgotten examples are removed from the training set. Most important examples tend to be those that are forgotten the most.
CAFE: Learning to Condense Dataset by Aligning Features (CVPR 2022)
ArXiv GitHub Condense dataset by Aligning FEatures (CAFE), which explicitly attempts to preserve the real-feature distribution as well as the discriminant power of the resulting synthetic set, lending itself to strong generalization capability to various architectures.
 Compared with gradient-based method our approach effectively captures the whole distribution thus generalizes well to other network architectures
Compared with gradient-based method our approach effectively captures the whole distribution thus generalizes well to other network architectures
Framework
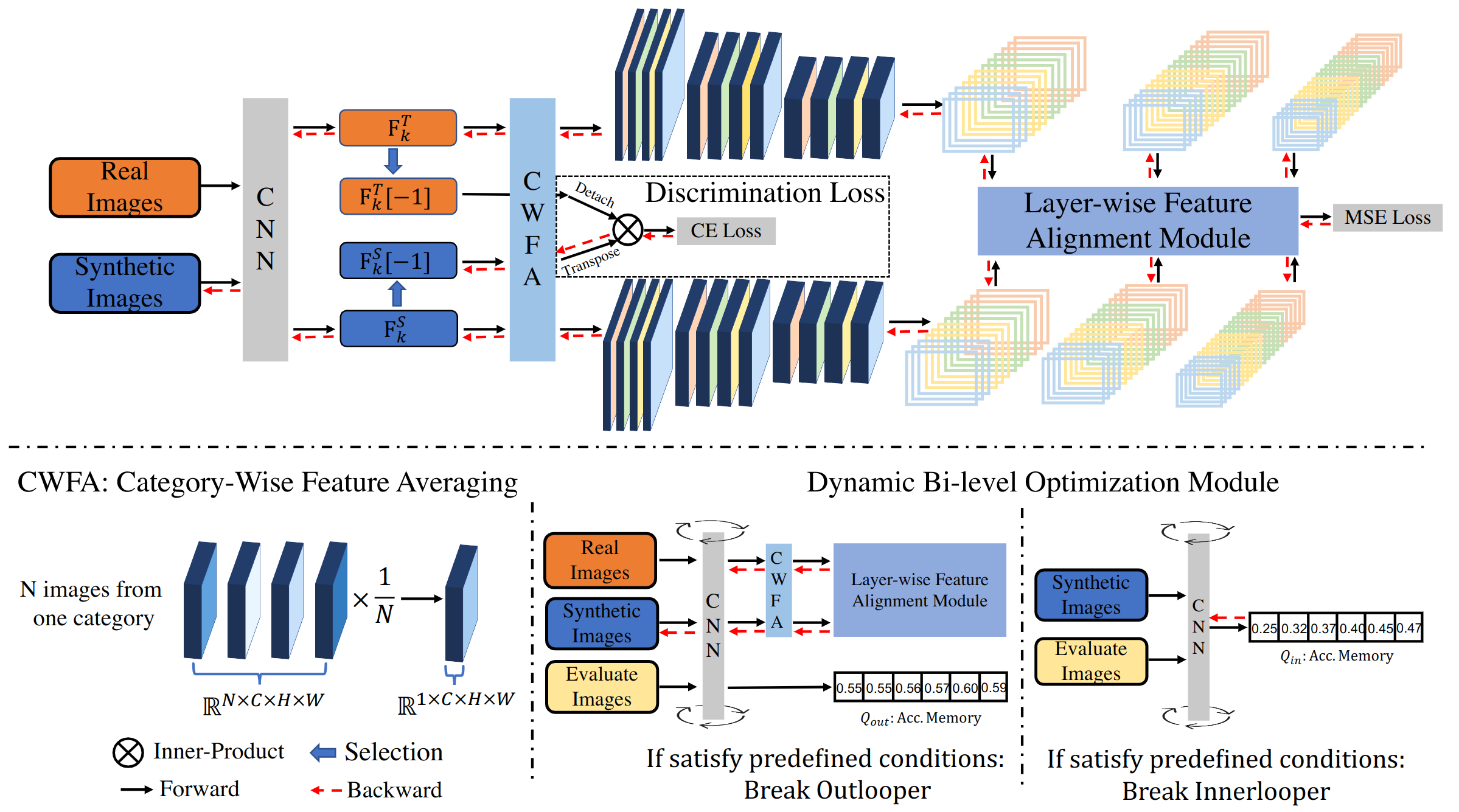
- a layer-wise feature alignment module to capture the accurate distribution of the original large-scale dataset
- a discrimination loss for mining the discriminate samples from real dataset
- a dynamic bi-level optimization module to reduce the influence of under- and over-fitting on synthetic images.
Resultes
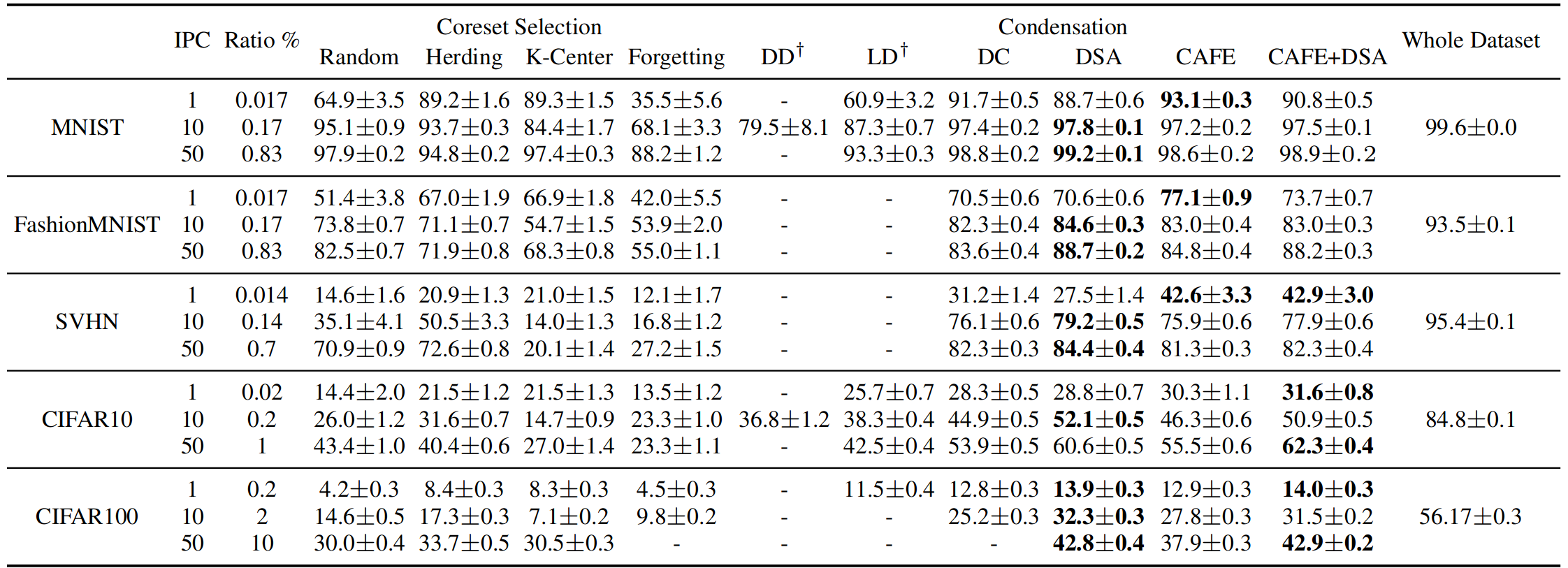
The performance (testing accuracy %) comparison to state-of-the-art methods.
 data distribution of real images and synthetic images by utilizing t-SNE to visualize the features
data distribution of real images and synthetic images by utilizing t-SNE to visualize the features

Dataset Condensation with Gradient Matching (ICLR 2021)
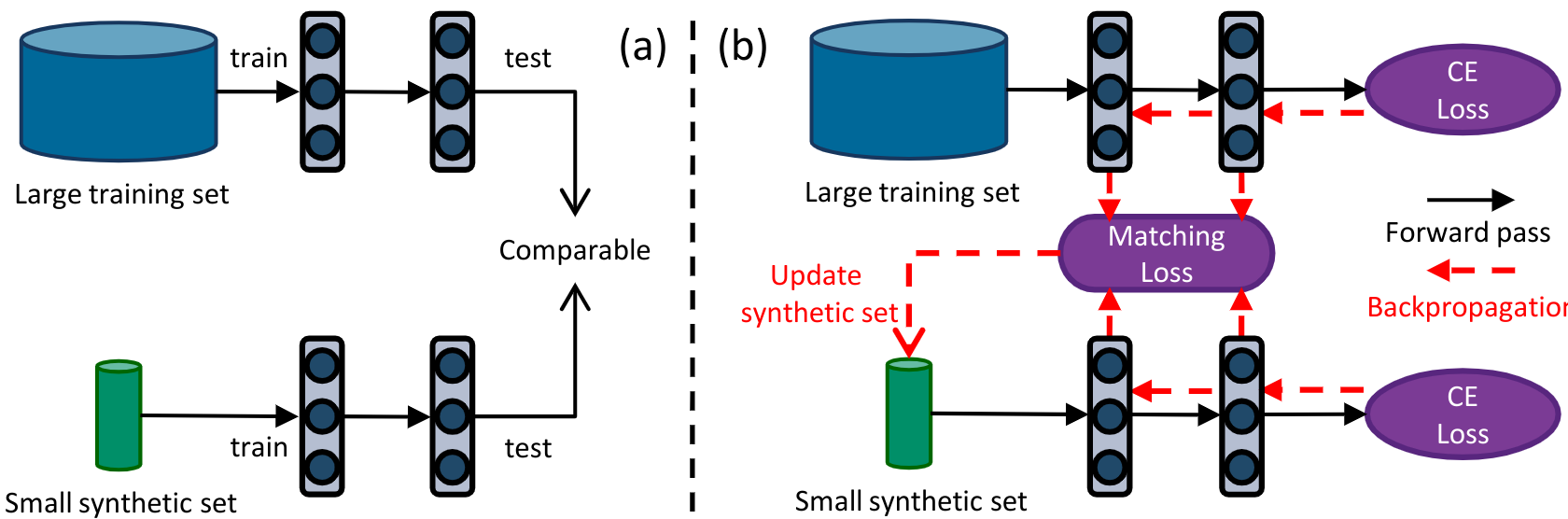
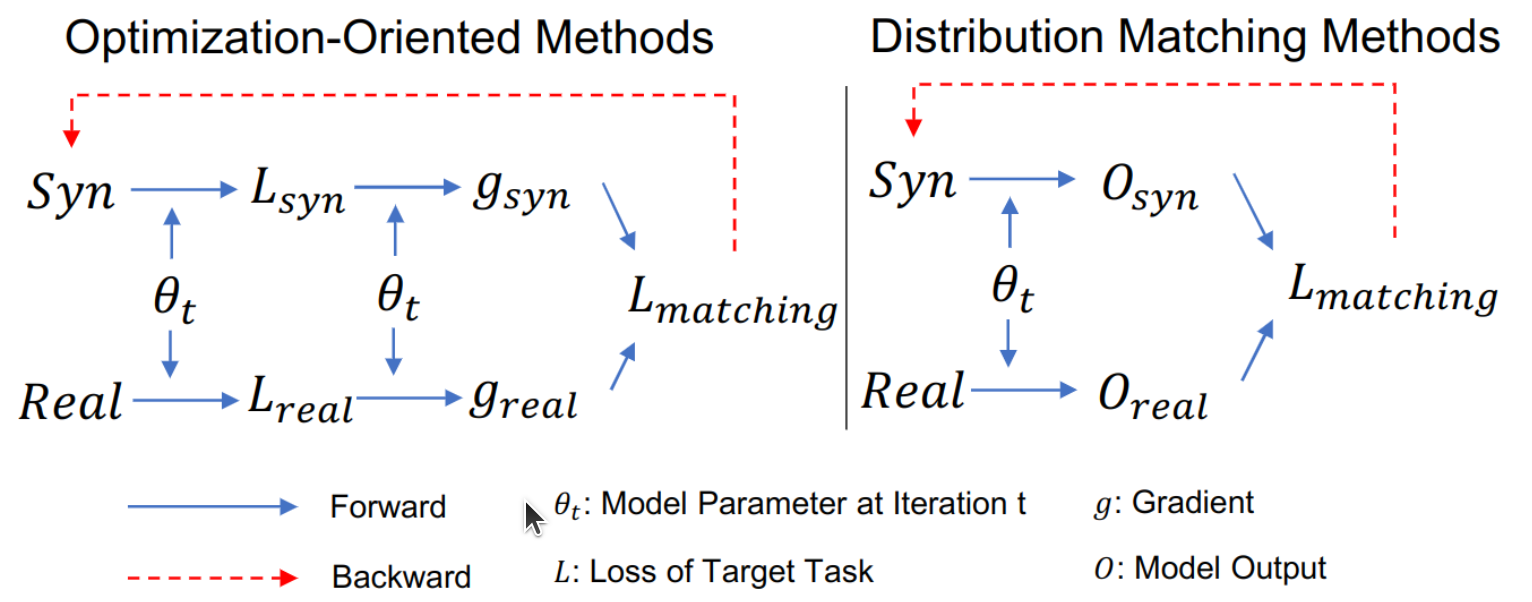
- (a)Dataset Condensation aims to generate a small set of synthetic images that can match the performance of a network trained on a large image dataset.
- (b)learning a synthetic set such that a deep network trained on it and the large set produces similar gradients w.r.t. its weights. The synthetic data can later be used to train a network from scratch in a small fraction of the original computational load.
Algorithm

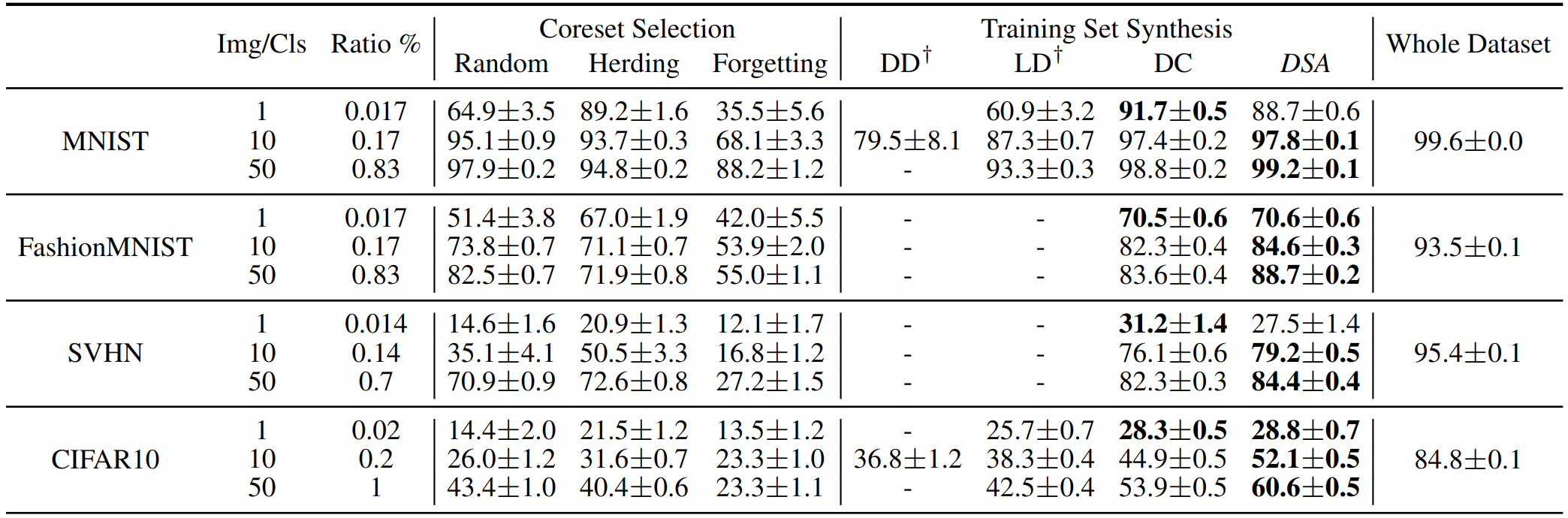
Resultes
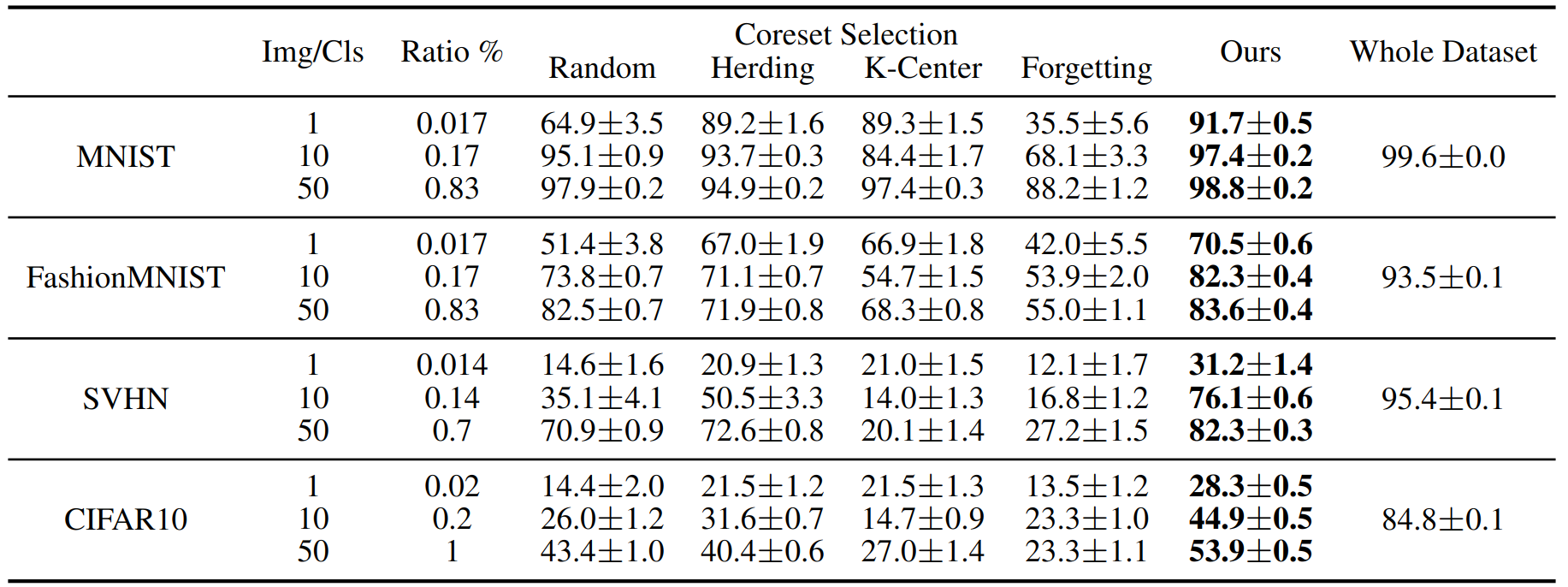
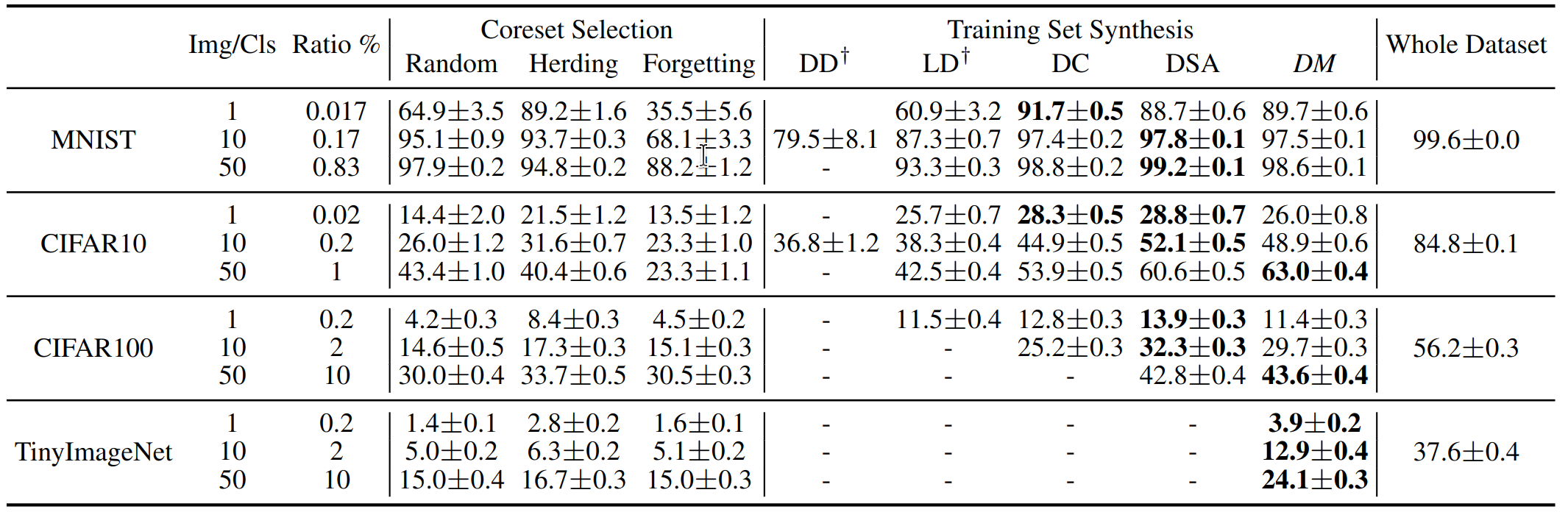
The performance comparison to coreset methods. This table shows the testing accuracies (%) of different methods on four datasets. ConvNet is used for training and testing. Img/Cls: image(s) per class, Ratio (%): the ratio of condensed images to whole training set.
 Visualization of condensed 1 im- age/class with ConvNet for MNIST, Fashion- MNIST, SVHN and CIFAR10.
Visualization of condensed 1 im- age/class with ConvNet for MNIST, Fashion- MNIST, SVHN and CIFAR10.

Dataset Condensation with Differentiable Siamese Augmentation (ICML 2021)
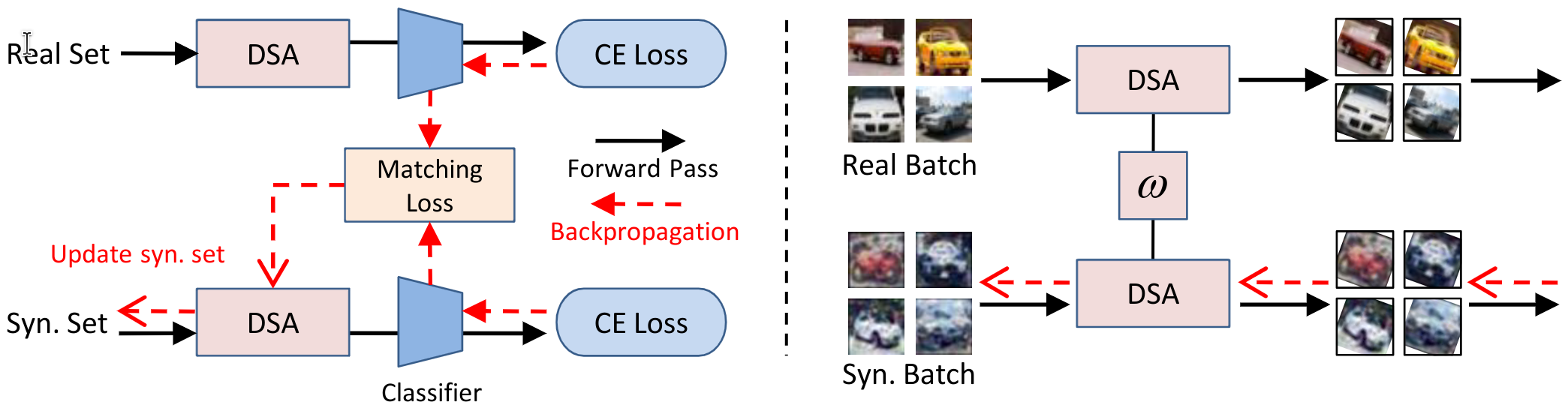
Differentiable Siamese augmentation (DSA) applies the same parametric augmentation (e.g. rotation) to all data points in the sampled real and synthetic batches in a training iteration. The gradients of network parameters w.r.t. the sampled real and synthetic batches are matched for updating the synthetic images. A DSA example is given that rotation with the same degree is applied to the sampled real and synthetic batches
- our method can exploit the information in real training images more effectively by augmenting them in several ways and transfer this augmented knowledge to the synthetic images.
- sharing the same transformation across real and synthetic images allows the synthetic images to learn certain prior knowledge in the real images (e.g. the objects are usually horizontally on the ground).
- most importantly, once the synthetic images are learned, they can be used with various data augmentation strategies to train different deep neural network architectures.
Algorithm

Resultes
Dataset Condensation With Distribution Matching (WACV 2023)
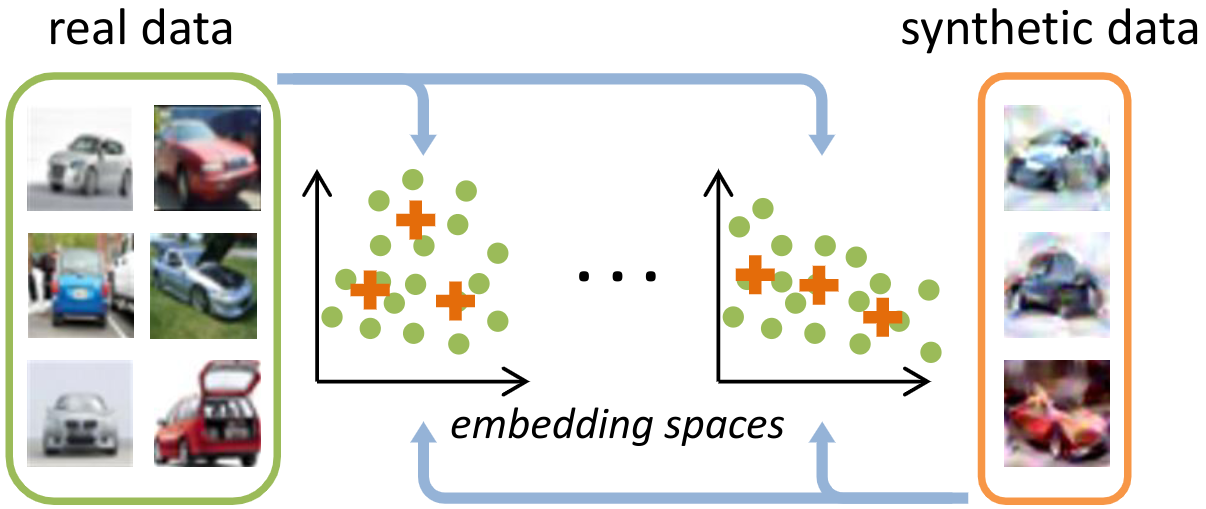
We randomly sample real and synthetic data, and then embed them with the randomly sampled deep neural networks. We learn the synthetic data by minimizing the distribution discrepancy between real and synthetic data in these sampled embedding spaces.
 estimate the distance between the real and synthetic data distribution with commonly used maximum mean discrepancy (MMD):
estimate the distance between the real and synthetic data distribution with commonly used maximum mean discrepancy (MMD):
Algorithm

Resultes

Samples With Low Loss Curvature Improve Data Efficiency (CVPR 2023)
Method
study the second order properties of the loss of trained deep neural networks with respect to the training data points to understand the curvature of the loss surface in the vicinity of these points.
- low curvature samples are largely consistent across completely different architectures, and identifiable in the early epochs of training. We show that the curvature relates to the ‘cleanliness’ of the data points, with low curvatures samples corresponding to clean,
- higher clarity samples, representative of their category. Alternatively, high curvature samples are often occluded, have conflicting features and visually atypical of their category.
Resultes
Histograms of curvature of the training set of CIFAR-10


Improved Distribution Matching for Dataset Condensation (CVPR 2023)
Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training (AAAI 2023)
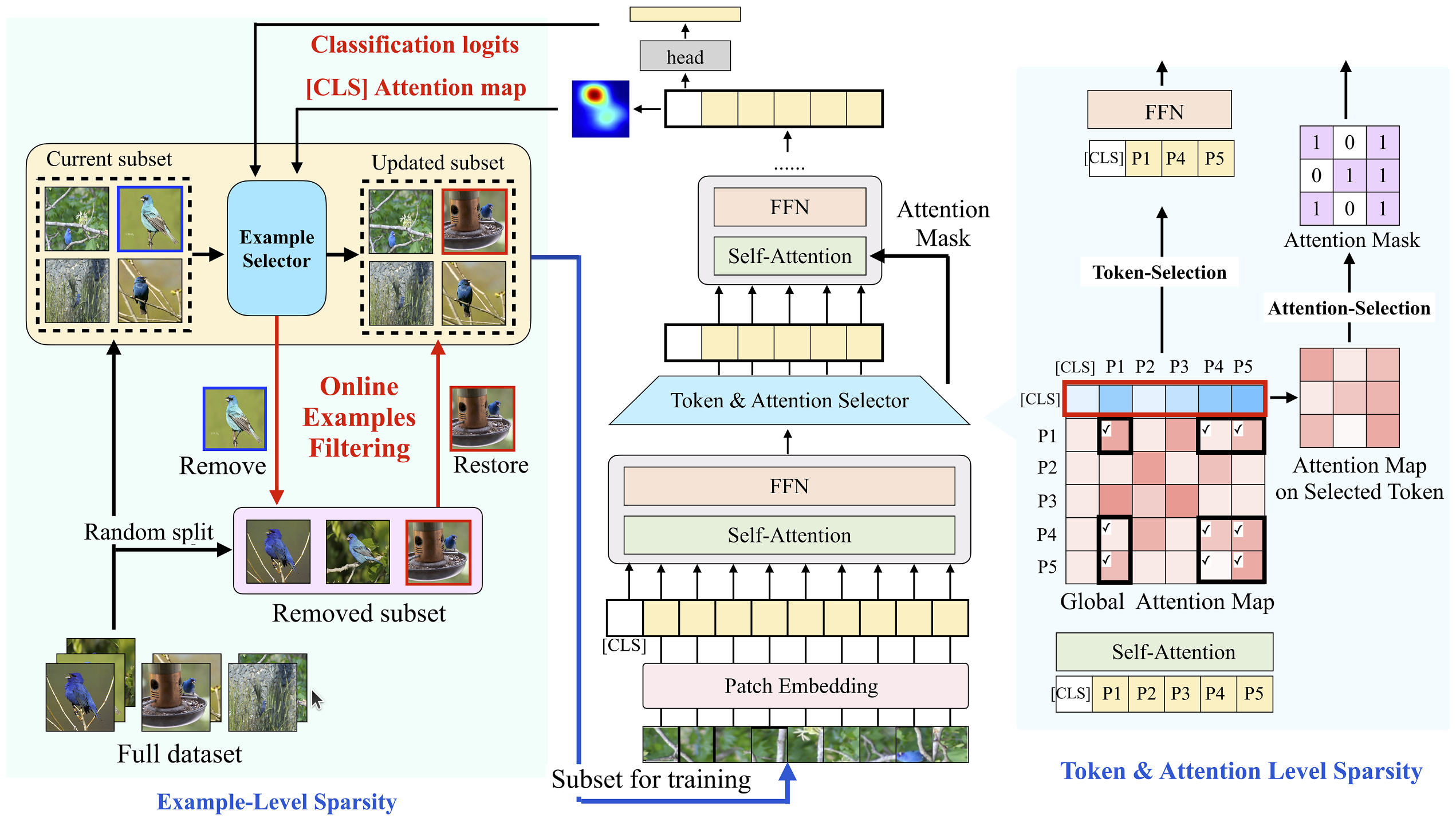
leverage a hierarchical data redundancy reduction scheme by exploring the sparsity under three levels:
- the number of training examples in the dataset,
- the number of patches (tokens) in each example,
- the number of connections between tokens that lie in attention weights.
 We explore the training sparsity under three levels:
We explore the training sparsity under three levels:
- Left: Example-Level Sparsity. Randomly remove a number of examples prior to training. During the training process, the example selector updates the training subset by removing the most unforgettable examples from the training data and restoring the same amount of data from the portion removed before training.
- Right: Token & Attention level sparsity. Evaluate token importance by the [CLS] token and prune the less informative tokens. We further use the attention vector of each remaining token to decide critical attention connections.
InstructionGPT-4: A 200-Instruction Paradigm for Fine-Tuning MiniGPT-4
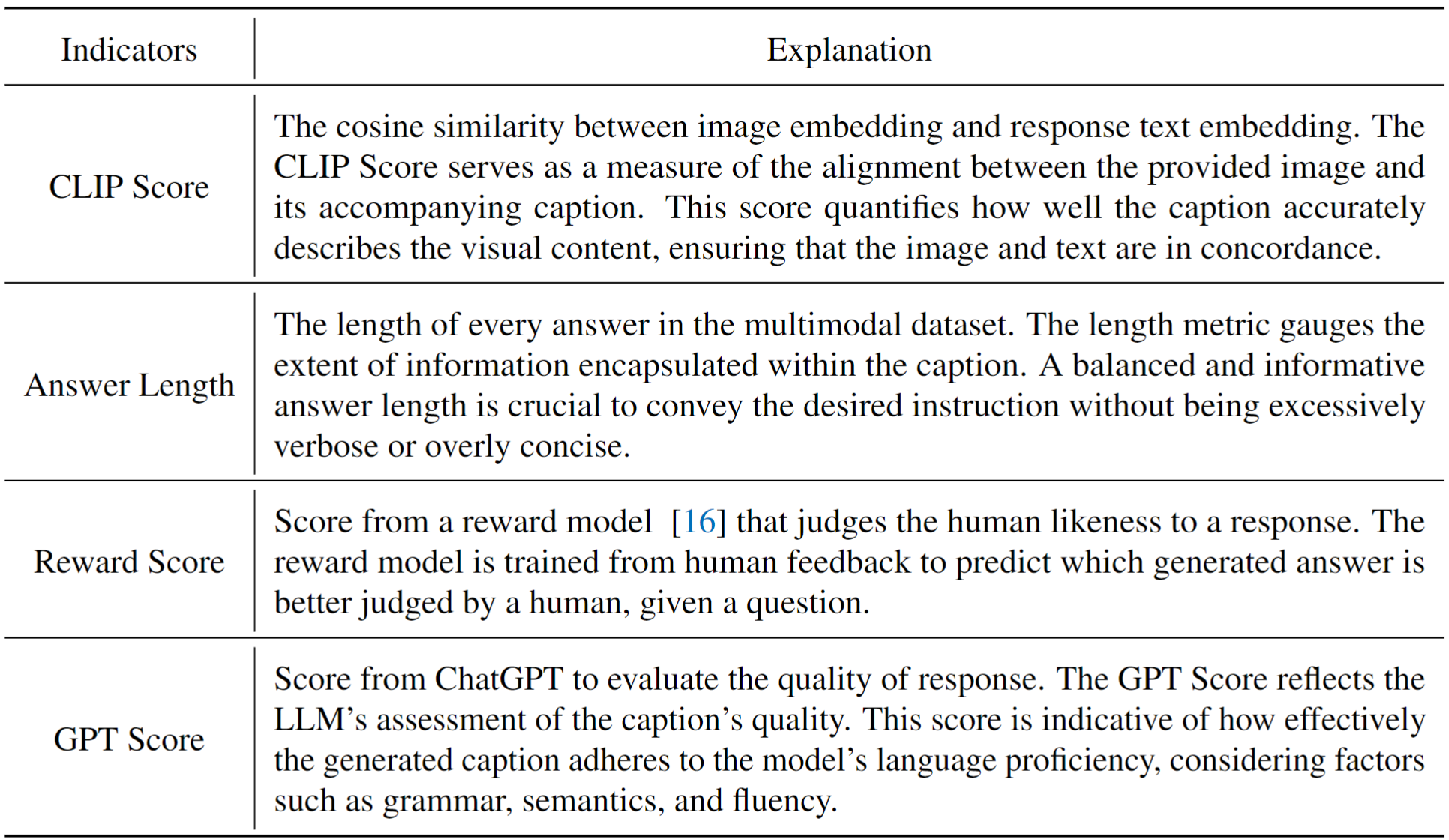
propose several metrics to access the quality of multimodal instruction data. Based on these metrics, we present a simple and effective data selector to automatically identify and filter low-quality vision-language data
Algorithm
